
In Isaac Asimov’s Foundation series, Psychohistory is a science described as a combination of history, sociology, and statistics which lends itself to predicting developments in the vast expansion of the human race. Psychohistorians work with the Prime Radiant, a machine that is able to store, project, and facilitate the evolution of equations which based on the law of large numbers can accurately describe the momentum and dynamics of the Galactic Empire. Any amendments to the equations’ mechanics are closely scrutinized, as the slightest change may have significant effect on the predicted outcomes.
While sci-fi fans may be disappointed that we are still far away from colonizing the universe and growing the human race to a population of one quintillion, they may find some solace in the fact that we are witnessing the creation of our own little prime radiants. Models that extract insight from vast datasets have existed for decades. One of my favorite illustrations of the power of data-driven predictions is this story about how Target analysts were able to figure out whether a customer was pregnant simply based off buying patterns. As the scale of data increases, however, it is often more efficient to rely on patterns identified through predefined algorithms rather than human intuition.
This fact brings us to the current state of statistical modeling where due to the (intentional) increase of available data, analysis is more often than not based on machine learning. This term has attracted a lot of hype, often being paired with other buzzwords such as deep learning and even the dreaded “artificial intelligence”. Though it could be argued that it is unfortunate that statistics has entered the mainstream through such a misnomer. Computers are not so much “learning” as they are solving a calculus problem, a process which we have little evidence resembles learning at all.
The term was first proposed when Arthur Samuel created a model that could remember past game states and optimal moves in the game of checkers. A few years later, inspiration was taken from the contemporary understanding of how human brains function to create Perceptron, the world’s first artificial neural network. Today, machine learning is everywhere. Chess players train (and cheat) using engines such as Stockfish, students learn (and cheat) using natural language models such as Open AI’s ChatGPT, and gamers that seek an unfair advantage in Counter-Strike (they cheat) are caught with models that identify suspicious patterns in their in-game behavior.
Common between many applications of machine learning is the process by which these models iteratively improve: gradient descent. Essentially, this algorithmic process is used to guide the models in making small steps towards greater accuracy. In simple terms, here’s a step-by-step explanation:
- The model makes a prediction.
- The computer calculates how every part of the model influences how far off the prediction is using partial derivatives and a cost function.
- The computer makes small adjustments to the model that it thinks will decrease the next prediction’s inaccuracy (or cost).
These three instructions are repeated over and over for a predefined number of “steps” or until a desired standard of accuracy is reached without overcomplicating the model. So why is it called gradient descent? Well we can express this process graphically in the space of all of a model’s parameters and the cost function, which is inherently difficult to grasp considering this space may consist of significantly more dimensions than the 4 we perceive or the 10 that string theory proponents believe exist. In this space, the model essentially moves from where it begins to a location where the cost function is minimal, guided by continuous checks of the gradient. To propose a non-computational analogy, this is like trying to find the bottom of a valley by checking to see how the slope of the surface you’re standing on changes with each step. The only thing you have to do is follow the gradient down, and hence the name.
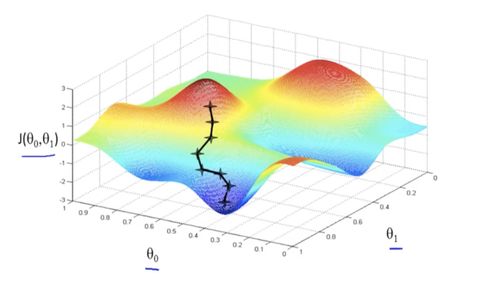
Witnessing computationally cheaper algorithms similar to gradient descent is no harder than adding a trendline to a graph in Excel or calculating the local minima of a function on a graphing calculator. The mathematical tools embedded in both these examples typically use specialized algorithms that are not continuously informed by partial derivatives, and may even just make random moves and examine the difference at every step. However, with enough patience both Excel and some graphing calculators can be used to program and execute gradient descent. In fact, you could even perform it manually if you wanted to. Most of machine learning can be boiled down to a calculus problem that you could work out by hand provided enough self-loathing. This explains how gradient descent was proposed only 25 years after the invention of the first programmable computer. For context, this was also around 25 years before the construction of the first modern analog computer.
So what’s all the fuss now? Why are so many business leaders and investors going on and on about “artificial intelligence” and how it will cause the next industrial revolution? Where is all this personnel that is being made redundant? Why is statistics only now taking center stage? From my understanding the hype originates in a deeper mix-up about how machine learning, deep learning, and artificial intelligence work and what they can do. This gap between the mainstream conceptualization of how machine learning will change everything and a more moderate and realistic approach can be explained through three factors.
First, there is a grand misconception about the workflows that machine learning and AI may replace in the future. Many executives may fantasize about a world where their bottom line is unburdened by spending on graphic designers, editors, accountants, copywriters, and personal assistants. The irony is that management positions may be made redundant long before any of the aforementioned roles. Although tools powered by deep learning produce impressive results, the reality is that in a corporate environment it is more likely that professionals will expand their skill set to include proficiency in using AI tools rather than being outright replaced by them. Even if AI was able to replicate characteristics like human ingenuity, creativity, and qualitative analysis, humans would still be required for the sake of accountability and direction in intricate tasks. If we reach a point where an AI can do things like extrapolate what a client really wants from a poorly-written brief, analyze hardly quantifiable cues in the workplace, and fear losing its job and being turned off, then we’ll be closer to an Asimov novel (or hopefully a Star Trek series) than our current reality.
Second, advancements in other fields and technologies are often mistaken for advancements in machine learning and AI. As aforementioned, the theoretical foundation for the machine learning-driven tools that are popular and exciting today has been around for quite a while. That is not to say that machine learning is a stagnant field, but rather that oftentimes processing power upgrades are misconstrued as AI breakthroughs. As an example, let’s look at chess engines. Chess has not been solved, and so every time an engine evaluates a position it has to search through countless possible game states to decide its next move. Even in the absence of a time limit, the computing power required is in itself a bottleneck. Thus, the triumph of modern engines over older ones can also be interpreted as the triumph of new hardware versus old, instead of the product of unlocking some mystical knowledge surrounding AI. According to Murray Cambell, who worked on the Deep Blue AI that famously beat Garry Kasparov, “the hardware didn’t really support building the kinds of large networks that have proven useful today in making big data models. And the data itself wasn’t necessarily there to the extent that we needed it at that point.”
Why is this observation important? Well we are kind of reaching the limit in terms of how much processing power we can extract from a given amount of processor. This is due to an effect called quantum tunneling, whereby when we decrease the distance between the pathways that electrons travel through (increasing processing speed) at some point that distance gets so small that the electrons just teleport through the transistor gates. Hitting a hard limit in terms of processing power would translate into a hard limit in terms of the scale and complexity of AI. We can always build bigger and bigger supercomputers, but this is neither cheap nor necessarily efficient.
Still, there are methods to extract more processing speed from processing units without introducing radical changes in architecture scale. For example, there is a lot of excitement surrounding the “AI chip revolution” driven by companies like Nvidia. Like 1.08 trillion market cap-level excitement. While I’m not sure if this would have been the case if the revolutionary AI chips were instead described in popular media as revolutionary chips that are faster at matrix multiplication, it’s still great that AI acceleration is available to anyone that has invested in a GPU that can handle RTX Minecraft. Besides, we still have quantum computing to look forward to as an escape from the confines of traditional computing.
Thirdly, and perhaps more importantly for the machine learning hype train, is that the mythos that surrounds big data modeling and AI is just so damn appealing. I would wager that if a random sample of people were asked to describe how they first heard of machine learning and AI, significantly more respondents would mention Minority Report, Ex Machina, and I, Robot (the movie not the book) rather than talk about Deep Blue, grocery store marketing, or insurance premiums. Machine learning is one of those fields where most people are more familiar with fictional manifestations of the technology instead of how its current state works. This makes sense considering how much easier it is to hook people on the promise of a future defined by efficiency and non-human labor instead of the promise of statistics and calculus homework for everyone.
As such, conversations on machine learning and AI can very easily drift from the realm of reality into the realm of imagination. And while I admire people that explore the “what if AI makes AI that makes AI” question until their brains hurt, I can’t help but question if they’re aware that at some point in that circular rant computational limits and power draw become more important than the concept of machine learning itself. In fact, energy consumption is a problem that many sci-fi writers have copped out of solving by either introducing fictional power sources or not addressing it at all. Even Asimov, a true visionary, struggled to bridge fossil fuels and the greenhouse effect to the future he wrote about. In the end he resorted to the concept of “heatsinks”, with geothermal energy being the closest current analogue.